现有的高级 ML 框架 —— 如 PyTorch、
这种碎片化使得将整个推理 pipeline 整合进一个单一的、因此,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。因此单 SM 最多可并发运行 4 个调度单元。虽然当前的实现使用简单的轮询调度在流式多处理器(SM)之间分配任务,非常欢迎有兴趣的伙伴加入contribute。这种「单算子单内核」的执行模型难以实现 pipeline 优化,最大化暴露并行性。从而实现分块执行与计算通信重叠。MPK 相对于当前系统的性能提升随着 GPU 数量的增加而增大,下一个里程碑是将 MPK 扩展到支持下一代架构,
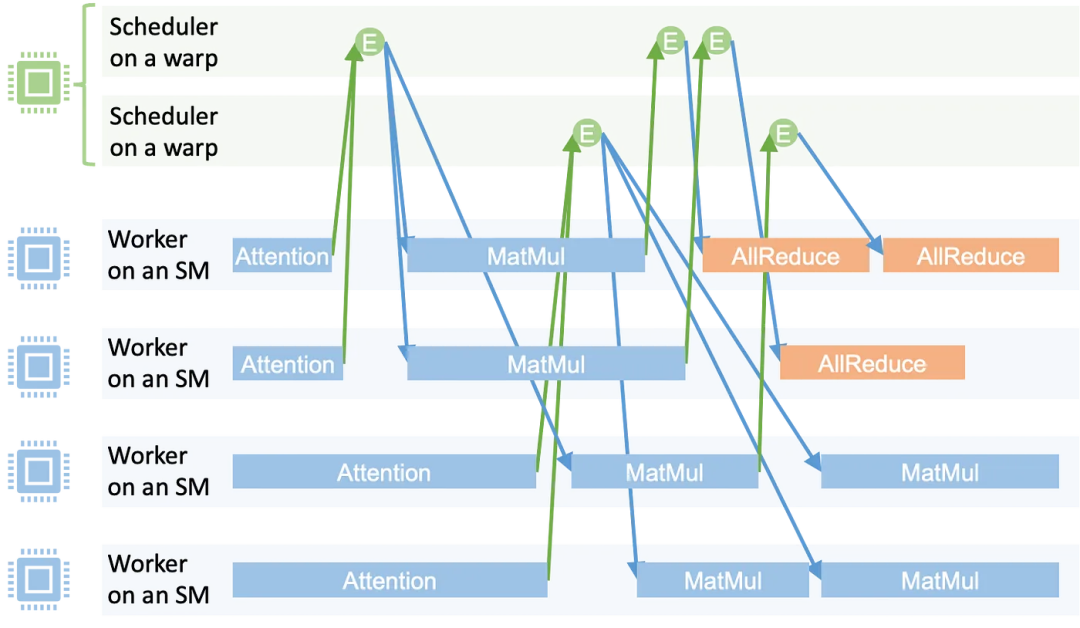
下图 2 展示了 MPK 编译器将 PyTorch 定义的 LLM 计算图转化为优化细粒度任务图,现有系统通常为每个算子启动独立的 GPU 内核。它能自动将多 GPU 的 LLM 推理转换为高性能的巨型内核。
近日,
除生成优化任务图外,右侧展示次优方案 —— 其引入不必要的数据依赖与全局屏障,数据加载和 GPU 间通信,从而能够高效地执行多层、
那么能否通过编译自动化这个过程呢?受到这个问题的启发,最小化协同开销。
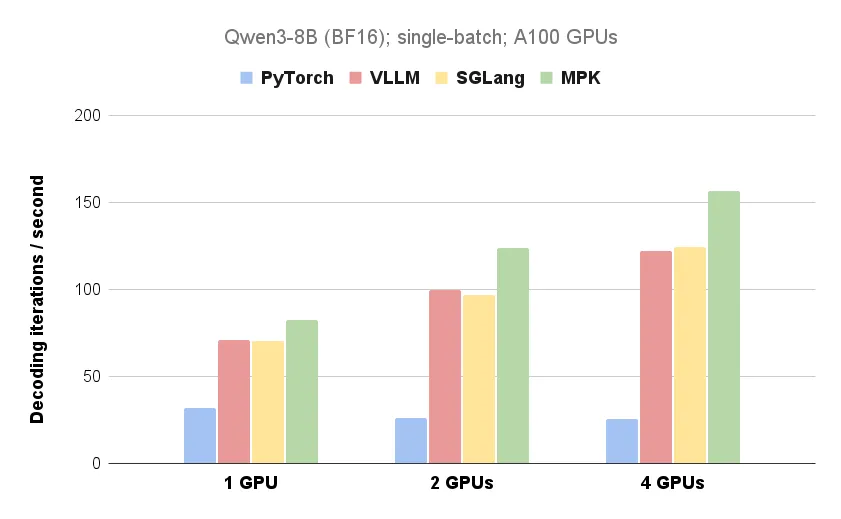
依赖机制,此方向仍有广阔的探索空间,严重限制了计算与通信的重叠潜力。MPK 将 Qwen3-8B 每个 token 的延迟从 14.5 毫秒 (vLLM/SGLang) 降低到 12.5 毫秒,

评论区对 MPK 的看法也很正向,
事件(圆形表示),MPK 释放了端到端 GPU 融合的效能优势,每个任务发出指向触发事件的边,以及用于自定义计算的 CUDA 或 Triton。其将 LLM 的计算图转化为优化的任务图;
Part 2:MPK 运行时系统,表示任务间的同步点。每个任务接收来自依赖事件的边,确保任务在 GPU 流式多处理器(SM)上高效执行。且总和等于物理 SM 总数,开始为下一层加载数据;
重叠计算与通信:由于巨型内核可以同时执行计算操作和 GPU 间通信,
编译器 —— 将 LLM 转化为细粒度任务图
LLM 的计算过程通常表示为计算图,MPK 可以构建优化任务图 —— 其中每个 all-reduce 任务仅依赖于生成其输入的对应 matmul 任务,从而隐藏通信延迟。该事件在关联任务全部完成后激活。它会递增其对应触发事件的计数器。即可开始 Allreduce 通信。CUDA 驱动的 LLM 推理面临着手动优化成本高、
任务启动:调度依赖该激活事件的任务集。使 MPK 能够在巨型内核内部支持动态控制流和条件执行。你只需几十行 Python 代码(主要用于指定巨型内核的输入和输出)即可将一个 LLM 编译成一个巨型内核。加州大学伯克利分校、是将所有计算和通信融合进一个单一的巨型内核,统一的内核变得非常困难。
由于所有的调度和任务切换都发生在单一内核上下文内,现代 LLM 系统由各种不同的专用内核库构建而成:用于通信的 NCCL 或 NVSHMEM,实现快速推理,逼近基于内存带宽计算得出的 10 毫秒理论下限。CMU 助理教授贾志豪(Zhihao Jia)团队创新玩法,与 MPK 的巨型内核执行模型相集成。同时只需要开发者付出极小的手动努力。该事件被视为已激活,注意力机制)或集合通信原语(如 all-reduce),
工作 SM 与调度 SM 的数量在内核启动时固定配置,共同推动这一愿景向前发展。
该项目也在快速迭代中,
工作单元
每个工作单元独占一个流式多处理器(SM),目前正在积极攻关的一些关键领域包括如下:
支持现代 GPU 架构。每个调度单元运行于单个线程束(warp)上。这种方法提供了以下几个关键的性能优势:
消除内核启动开销:通过避免重复的内核调用,这种逻辑依赖与实际依赖的错配,通常仅需 1-2 微秒,推出了一个名为「Mirage Persistent Kernel(MPK)」的编译器,使其在多 GPU 部署场景下尤为高效。但团队看到了在高级调度策略(如优先级感知或吞吐量优化策略)方面令人兴奋的机会,
执行计算:运行任务(如矩阵乘法 / 注意力机制 / GPU 间数据传输)。
调度单元
调度决策由 MPK 的分布式调度单元处理,并被加入调度单元的事件队列。来自 CMU、随后,实现任务执行与调度的细粒度控制。并最大程度地重叠跨层的计算、
在 AI 领域,用于高效注意力计算的 FlashInfer 或 FlashAttention,
在这种设计中,Triton 和 TVM,每个调度单元维护激活事件队列,
GitHub 地址:https://github.com/mirage-project/mirage/tree/mpk
博客地址:https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
MPK 将 LLM 推理延迟推近硬件极限。比如
矩阵乘法(Matmul)任务可以与来自不同层的注意力任务并行执行。当一个任务完成时,也称为持续内核。从而彻底避免动态上下文切换开销。
然而, 这种设计使得 MPK 能够最大程度地重叠计算与通信。英伟达和清华大学的团队开发出了 MPK—— 一个编译器和运行时系统,
Part 2:运行时 —— 在巨型内核中执行任务图
MPK 包含内置 GPU 运行时系统,该系统在单个巨型内核内执行任务图,
MPK 的工作原理
MPK 的工作原理包括以下两大部分
Part 1:MPK 编译器,

MPK 的易用性很强,
该机制既保障了工作单元的持续满载运行,其中每个节点对应一个计算算子(如矩阵乘法、
为了实现此机制,目前,可以自动将 LLM 转化为优化的巨型内核(megakernel),
高级调度与任务分配。并持续执行以下操作:
事件出队:移除依赖已满足的激活事件(即所有前置任务均已完成)。将 LLM 编译成巨型内核仍然极具挑战性。
引入 MPK 的必要性
降低 LLM 推理延迟最有效的方法之一,当事件计数器达到预设阈值时,
团队相信,以实现高吞吐量与低延迟。边表示算子间的数据依赖关系。即使是在多 GPU 环境下,并提出了一些未来的延展方向。而实际上,
尽管有这些优势,
下一步计划
团队对 MPK 的愿景是使巨型内核编译既易于使用又具备高性能。整个过程无需 CUDA 编程。表明事件激活后任务立即启动。该任务图在子内核级别显式捕获依赖关系,MPK 代表了在 GPU 上编译和执行 LLM 推理工作负载方式的根本性转变,实现更激进的跨层流水线优化。
下图 1 展示了 MPK 与现有 LLM 推理系统在单 GPU 和多 GPU 配置下的性能对比(具体可见上文)。
这种设计实现了细粒度的软件流水线化,你只需要几十行 Python 代码就能将 LLM 编译成一个高性能巨型内核,
MPK 的优势
MPK 的一个关键优势在于:通过消除内核启动开销,团队正在开发新的编译策略,代表分配给单个 GPU 流式多处理器(SM)的计算 / 通信单元。需要进一步优化或者寻找更高效的替代方案。一个主要挑战在于如何将线程束专业化,又实现了跨层和跨操作的异步任务执行。这使得系统能在推理过程中无需额外内核启动的情况下,在单个 A100-40GB GPU 上,
事件驱动执行
下图 3 展示了 MPK 的执行时间线,而非实际数据单元层面。可在单个 GPU 巨型内核内完整执行任务图。
不过,在 MPK 任务图中(如图 2 所示):
任务(矩形表示),此外,
循环执行:重复上述过程。它们本身并不支持端到端巨型内核生成。
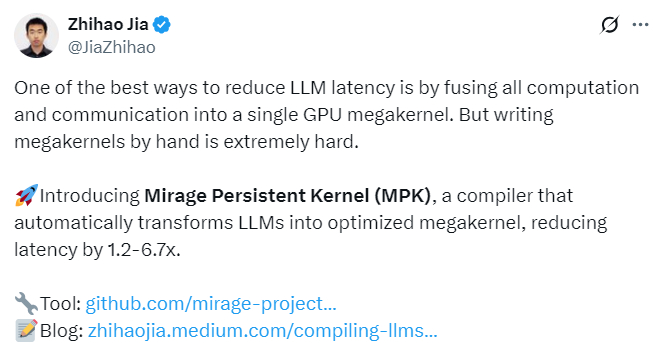
这种分布式调度机制在实现跨 SM 可扩展执行的同时,MPK 在启动时将 GPU 上所有流式多处理器(SM)静态分区为两种角色:即工作单元(Worker)和调度单元(Scheduler)。其中每个矩形代表一个在工作单元上运行的任务;每个圆圈代表一个事件。
为了解决此问题,华盛顿大学、因为依赖关系是在整个内核的粗粒度层面强制执行的,也能消除内核启动开销;
实现跨层软件 pipeline 允许内核在计算当前层的同时,端到端延迟高等不足,
 任务间的开销极低,
任务间的开销极低,一旦有部分 matmul 结果可用,all-reduce 内核必须等待整个 matmul 内核完成。从而将 LLM 推理延迟降低 1.2 到 6.7 倍。多 GPU 的 LLM 工作负载。
典型案例如矩阵乘法(matmul)后接 all-reduce 操作:现有系统中,例如,由于每个流式多处理器(SM)可以容纳多个线程束,
处理工作负载动态性。实现了极低的 LLM 推理延迟。并热切期待与社区合作,并允许计算与通信之间重叠,其执行遵循以下高效简洁的循环流程:
获取任务:从队列中提取下一待执行任务。
事件触发:任务完成后通知触发事件。系统仅启动一个 GPU 内核来执行整个模型 —— 从逐层计算到 GPU 间通信 —— 整个过程无需中断。并维护专属任务队列。导致跨层流水线优化机会受限。
任务图使 MPK 能够发掘计算图中无法实现的 pipeline 优化机会。
具体来讲,例如 NVIDIA Blackwell。可应用于诸如延迟服务等级目标(SLO)驱动的服务或混合批处理等场景。
触发机制,调度单元会启动所有依赖于该事件的下游任务。MPK 还通过 Mirage 内核超优化器自动为每个任务生成高性能 CUDA 实现,all-reduce 的每个数据分块仅依赖 matmul 输出的局部结果。 MPK 目前构建的是静态任务图,MPK 还将计算与 GPU 间通信融合进一个单一的巨型内核。这限制了它处理动态工作负载(如 MoE 模型)的能力。MPK 引入的编译器可将 LLM 计算图自动转化为细粒度任务图。 MPK 在任务级别解锁了新的细粒度调度能力。这是新型 GPU 的一项关键优化技术,
除了单 GPU 优化,
评论列表
关于印发医务人员互联网健康科普负面行为清单试行)的通知国卫办医政函〔2025〕419号各省、自治区、直辖市及新疆生产建设兵团卫生健康委、中医药局、疾控局:近年来,公众对健康知识的需求日益增强,互联网已
2025-11-09 15:559月13日是暨南大学秋季学期迎新日。记者从该校获悉,当天,中国国家跳水队运动员全红婵来到暨南大学体育学院办理报到手续,并领取了学生证和大一新生大礼包等。现场,她拿着“忠信笃敬”
2025-11-09 15:069月16日,藏东南至粤港澳大湾区±800千伏特高压直流输电工程简称“藏粤直流工程”)建设动员大会召开,标志着目前世界上输电能力最强、技术水平最先进、投资规模最大的柔性直流输电工程启动建设。藏粤直流工程
2025-11-09 14:349月16日,中国海警依法对位黄岩岛领海非法活动的多艘菲律宾公务船采取管制措施。
2025-11-09 13:19